
Last Updated on April 24, 2026 by Team TBH
AI has rocketed from proof-of-concept to board priority, and raw compute is now the finish line. Training a single large-language model can consume thousands of high-end GPUs and enough electricity to power a small city, turning infrastructure into a strategic asset.
Cloud giants are pouring billions into GPU farms while start-ups snap up every new card NVIDIA ships. In that scramble, enterprise teams juggle roadmaps, security, and budgets—all while racing to secure scarce capacity.
This guide distills hardware roadmaps, real-world pricing, and customer proof into a clear comparison of the five providers that matter most for enterprise-grade AI today.
How we ranked the field

You’re about to invest real budget and mission-critical workloads on another vendor’s silicon, so the rankings must stand on more than marketing copy. We pulled the latest hardware disclosures, public pricing calculators, benchmark runs, and customer proof from 2024 and 2025. Then we cross-checked every claim against practitioner chatter in developer forums, because glossy PDFs don’t capture the 2 am pain of a stalled quota request.
From that evidence, five platforms rose to the top. Each cleared a non-negotiable bar: access to current-generation GPUs or custom accelerators, secure multitenant design, and an established record of large-language-model workloads at scale. Three are the hyperscalers you know. One is a GPU specialist. One is the integrator enterprises trust to tie everything together.
We scored each provider across five pillars: performance and scalability, cost efficiency, ecosystem depth, enterprise support plus compliance, and pace of change. Hardware specs and network bandwidth shaped performance. Transparent on-demand rates, spot savings, and hidden fees determined cost. Managed ML services, data tools, and marketplaces defined ecosystem strength. Compliance badges and SLAs showed enterprise readiness. Finally, public roadmaps and unique silicon plays revealed who will keep you ahead tomorrow.
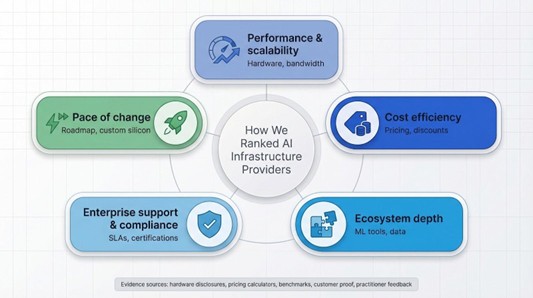
The outcome is a shortlist grounded in data, not hype.
TD SYNNEX, the integration partner
Most enterprises don’t begin their AI journey by spinning up GPUs. They start by figuring out which mix of on-prem hardware, public cloud, and governance tools will satisfy the board. TD SYNNEX fills that gap. Picture a general contractor for AI projects who assembles the right parts, vendors, and compliance wrappers so you don’t have to.
Branded as Destination AI, TD SYNNEX acts as an AI technology partner, wrapping immersive workshops, prescriptive playbooks, and a 90-day execution roadmap into one engagement that turns fuzzy AI ambition into concrete results. The headline “AI Game Plan” workshop moves through three brisk phases: surface high-impact use cases, score each for feasibility and ROI, then commit funding to the winners.
Because TD SYNNEX is vendor-neutral, you can leave with a design that mixes an on-prem NVIDIA DGX pod for steady training, CoreWeave burst capacity for spikes, and Azure OpenAI endpoints for production inference. The team brokers hardware, negotiates cloud commits, and keeps every SLA honest. That neutrality often saves more than it costs by avoiding mis-sized clusters and surprise egress bills.
If your charter is “make AI real” rather than “manage servers,” this partner keeps you focused on outcomes instead of plumbing.
Amazon Web Services, the everything cloud
AWS offers the widest range of AI hardware on the planet and keeps adding new options. The flagship P5 instance family pairs eight NVIDIA H100 GPUs with 3 200 Gbps of NVLink bandwidth. AWS first previewed the design as a 20-exaflop supercomputer for rent and later moved it into general availability.
That capacity scales quickly. Customers can link hundreds of P5 nodes in a single UltraCluster using petabit-scale Elastic Fabric Adapter networking and finish multi-billion-parameter training runs in days instead of weeks. When budgets tighten, you can switch to Trainium chips for FP16 training or Inferentia2 for inference without touching your code.
Cost is the trade-off. On-demand H100 time sits above $5 per GPU-hour, and unexpected egress or storage I/O charges can catch teams off guard. Spot discounts up to 70 percent and deeper rates on long-term Savings Plans help, but a sharp pencil still matters.
The upside is everything else in the box. S3 streams data straight to GPUs, SageMaker automates pipelines, and a marketplace of third-party models lets you spin up production endpoints with a few API calls. Compliance coverage is equally broad, spanning HIPAA to FedRAMP High.
If you need a single provider that can handle a proof of concept on Monday and a global rollout by Friday while meeting enterprise security requirements, AWS remains a safe, albeit premium-priced, pick.
Microsoft Azure, the supercomputer in a suit
Azure wears two hats at once: polished enterprise platform and raw GPU powerhouse. That mix comes from Microsoft’s multibillion-dollar alliance with OpenAI, which pushed Azure to build some of the world’s largest H100 clusters just to keep GPT-4 online.
Those clusters now sit on the public price list. New NC and ND H100 virtual machines let you pick one, two, or eight GPUs per node and link them with InfiniBand for near-linear scaling. DeepSpeed and ONNX Runtime arrive pre-tuned, so you squeeze every tensor from the silicon without wrestling driver issues.
Integration is the real ace. Azure OpenAI Service places GPT-4, DALL·E, and other frontier models behind your tenant’s virtual network, complete with RBAC and data residency controls the CISO can sign off on. Pair that with Synapse Analytics, Power BI, and Teams, and you move from prototype to customer-facing feature inside the stack you already pay for.
Capacity is the sore spot. Microsoft notes that demand can outrun electrical supply, so large GPU quota requests need planning. Pricing matches AWS unless you reserve instances or fold spend into a broader Microsoft enterprise agreement.
If your company lives in the Microsoft ecosystem, Azure feels like home. Credentials flow through Active Directory, DevOps pipelines live in GitHub, and support tickets route through the same Premier account team you rely on today. For many CIOs, that familiarity turns Azure’s supercomputer into a safe, board-friendly upgrade.
Google Cloud Platform, the TPU advantage
Google Cloud tackles AI with its own engine: the Tensor Processing Unit, or TPU. This custom chip chews through matrix math faster and more efficiently than a comparable GPU.
A single TPU v4 pod delivers roughly one exaflop of mixed-precision compute. If your models run on JAX or TensorFlow, these pods can shorten training cycles and trim energy bills in one move. For workloads that prefer NVIDIA, GCP’s A3 instances provide H100 power on familiar drivers, so you stay flexible.
Hardware is only half the story. Vertex AI joins data prep, distributed training, and auto-scaled endpoints in one console. BigQuery sits a few clicks away, ready to stream terabytes straight into your training loop. That tight coupling is a lifesaver when your data already lives in Google’s analytics stack and time-to-insight matters more than cloud comparisons.
GCP’s challenges sit outside the lab. TPU regions remain limited, and large-scale quota approvals can take longer than you might expect. On-demand rates match other hyperscalers, but Google’s discounts rely on sustained use, so finance teams need solid utilisation models.
When you need raw speed and an open-source friendly toolkit, GCP turns infrastructure into a performance multiplier. Combine TPUs for headline projects with commodity GPUs for day-to-day tasks and you gain headroom without losing budget discipline.
CoreWeave, the specialist that stretches your budget

CoreWeave started in crypto mining but matured quickly once generative AI arrived. Today the company runs warehouses packed with the latest NVIDIA silicon and rents that power with the speed and flexibility of a start-up.
Fast access is the hook. While hyperscalers released H100 capacity in small batches, CoreWeave offered full clusters in 2023 and already has slots reserved for Blackwell GPUs as soon as they ship. Provisioning feels like take-out: pick your GPU, choose a Kubernetes template, and watch a fresh node appear in minutes.
Price seals the deal. An on-demand H100costs about $2.75 per hour—roughly half the rate on AWS or Azure. Billing is to the second, in-region data transfer is free, and spot instances cut the bill even further. For teams counting every training dollar, that gap matters.
Focus has trade-offs. CoreWeave doesn’t provide a managed data lake or a polished MLOps studio. Compliance certificates are improving but still trail the hyperscalers. And with data centers limited to North America and Western Europe, latency can pinch real-time inference workloads.
Choose CoreWeave when raw compute is the bottleneck and you already own the surrounding tooling. It shines for bursty LLM training, VFX rendering weeks, or any sprint where trimming millions from the GPU bill outranks having a one-stop cloud.
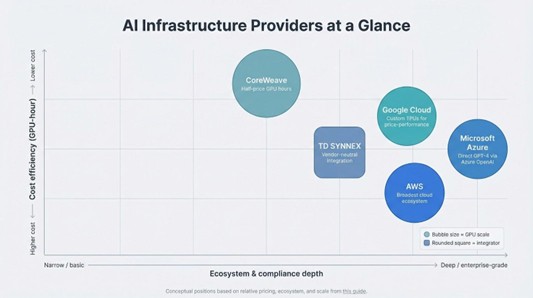
At-a-glance comparison
Numbers seldom capture every nuance, yet the matrix below highlights hardware, pricing, scale, and one standout advantage for each provider so you can compare them in seconds.
| Provider | Headline hardware | Indicative H100 price (per GPU-hr) | Maximum scale | Unique edge | Compliance snapshot |
| TD SYNNEX | Multi-vendor (DGX, Azure Stack, on-prem clusters) | n/a (consultative) | Dependent on partner capacity | Vendor-neutral integration expertise | Partner certifications cover HIPAA, FedRAMP, GDPR |
| AWS | P5 instances with 8 × H100 and 3 200 Gbps NVLink | ≈ $5 – $6 | UltraClusters with thousands of GPUs | Broadest cloud ecosystem | ISO 27001, SOC 2, FedRAMP High, HIPAA |
| Microsoft Azure | NC/ND H100 VMs on global fabric | ≈ $5 – $6 | GPT-scale superclusters | Direct access to GPT-4 through Azure OpenAI | ISO series, SOC 2, FedRAMP High, HIPAA, GDPR |
| Google Cloud | A3 H100 VMs plus TPU v4 pods | ≈ $4 – $5 | Exaflop-class TPU pods | Custom TPUs for price-performance wins | ISO series, SOC 2, HIPAA, GDPR |
| CoreWeave | Bare-metal H100, A100, RTX, AMD MI300X (planned) | ≈ $2.75 – $3 | 1 000-GPU clusters provisioned in minutes | Half-price GPU hours and per-second billing | SOC 2 Type II; more pending |
Use the grid to match your priorities. If regulated data is essential, focus on the hyperscalers’ certification lists. If budget rules the day, CoreWeave’s rate card stands out. When strategy matters more than server management, TD SYNNEX’s integration skill carries weight.
Every figure is a snapshot. Prices change, new chips launch, and regions open. Treat this table as a compass, then validate the direction with a quick proof of concept before you commit real budget.
Five buying questions to ask before you sign
Hardware tables help, but buying decisions happen in conference rooms where people weigh budgets, deadlines, and risk. Use these five questions to cut through the noise and land on an infrastructure plan everyone can endorse.

First, performance versus cost. Don’t chase the lowest hourly rate; aim for the lowest total training bill. Run a six-hour benchmark on two providers and compare both the clock and the invoice. Faster silicon that finishes early often wins.
Second, scalability today and tomorrow. Can the vendor hand you a thousand GPUs next quarter when your model jumps from seven to seventy billion parameters? Check roadmap slides and, more important, quota approval times.
Third, ecosystem fit. Where does your data live, which MLOps stack do you trust, and which compliance guards are non-negotiable? A smooth pipe from storage to GPU saves more engineering hours than any discount.
Fourth, support and reliability. When an H100 node fails mid-epoch at 3 am, who answers the phone? Hyperscalers sell tiered support; specialists offer Slack channels with real engineers. Pick the style your team will use.
Fifth, flexibility for a multi-cloud world. Lock-in is expensive insurance. Containerised workloads, portable data formats, and partners such as TD SYNNEX keep you free to burst or migrate when prices shift or regulations land.
Walk through these questions with finance, security, and engineering in the same room. The right answer usually emerges long before the slide deck ends.
Conclusion
Choosing the right AI infrastructure provider is a balancing act across performance, cost, ecosystem, and long-term flexibility. The five options profiled here each lead in different dimensions—from CoreWeave’s aggressive pricing to Azure’s deep enterprise integration. Use the comparison matrix and buying questions as a framework, validate assumptions with targeted proofs of concept, and you’ll secure the compute your models need without compromising budgets or compliance.
To read more content like this, explore The Brand Hopper
Subscribe to our newsletter


