
Last Updated on August 14, 2025 by Team TBH
RudderStack is a venture-backed startup that provides customer data infrastructure through a warehouse-native Customer Data Platform (CDP) built for developers.
Founded in 2019 and headquartered in San Francisco, RudderStack enables organizations to collect, unify, and route customer data in real time without storing it on a third-party server. The company’s platform emphasizes a “warehouse-first” approach: data is ingested and processed but ultimately resides in the customer’s own data warehouse or lake, alleviating privacy and compliance concerns.
Since its inception, RudderStack has positioned itself as an open-source alternative to traditional marketing-focused CDPs like Segment, focusing on data engineers’ needs.
This article presents an in-depth look at RudderStack’s founding, leadership, business model, revenue streams, funding history, competitive landscape, and strategic advantages, with the most current information available as of 2025.
Each section provides a factual, evidence-based analysis of how RudderStack has built its brand and competes in the customer data infrastructure market.
Founding Story of Rudderstack
RudderStack was born out of the firsthand frustrations its founder experienced in managing customer data at scale. Soumyadeb Mitra, who holds a PhD in Computer Science from the University of Illinois at Urbana-Champaign, previously founded a machine learning startup (Mariana) that was acquired by communications company 8×8 in 2018. At 8×8, Mitra led the machine learning team and was tasked with building an internal customer data platform, encountering the complexity of integrating myriad data sources to achieve a unified customer view.
This experience highlighted the gap in the market for developer-friendly customer data infrastructure.
In 2019, Mitra partnered with Shvet Jain, a venture partner at S28 Capital, to incubate a new company addressing this need.
The startup, initially called RudderLabs, launched the open-source project RudderStack in late 2019 as an event streaming pipeline and CDP for developers. Its timing was propitious: the broader industry was recognizing the value of customer data platforms (Twilio announced a $3.2 billion acquisition of Segment in late 2020), validating the importance of infrastructure that RudderStack set out to provide.
RudderStack’s founding vision was to give companies an easier way to build a “future-proof” customer data stack – one that could handle real-time event collection, ensure data quality, and feed analytics and machine learning models, all while keeping data under the customer’s control. This vision resonated with early adopters, and by mid-2020 RudderStack had released its first stable versions, leveraging an open-source community to drive rapid product iterations.
The founding story of RudderStack is thus rooted in a practical engineering problem encountered in industry, which shaped its core principle: make customer data easy for engineers, not just marketers.
Founders of RudderStack
Soumyadeb Mitra is RudderStack’s founder and CEO, and the driving force behind its technical vision. A second-time founder, Mitra’s background blends deep technical expertise with entrepreneurial experience.
His first company, Mariana (a marketing AI startup), was acquired in 2018, after which he built customer data and machine learning systems at 8×8, a cloud communications provider. Mitra’s academic credentials (a PhD in database systems) and industry experience gave him insight into the challenges of scalable data pipelines, informing RudderStack’s emphasis on robust architecture.

Mitra is joined by Shvet Jain as a co-founder in an executive chairman role. Jain is a partner at S28 Capital, the venture firm that incubated RudderStack, and he provided early capital and go-to-market guidance. Together, they assembled a globally distributed engineering team in the company’s early days – leveraging talent in India and Greece to build the product cost-effectively.

This lean, engineering-centric team culture was set by the founders from the start. By 2021, RudderStack’s team had tripled to support growth, and by 2023 the company grew to around 150 employees globally.
The founders’ complementary strengths – Mitra’s technical leadership and Jain’s venture guidance – have been pivotal in RudderStack’s journey. Under their leadership, RudderStack has maintained a clear focus on developers as its core users, differentiating the company’s brand in a crowded customer data technology space.
Business Model of RudderStack
RudderStack’s business model blends open-source community adoption with a cloud-based Software-as-a-Service (SaaS) offering.
At its core, RudderStack is an open-source platform: the source code for the RudderStack server is available publicly, allowing developers to self-host the infrastructure if they choose. This open-core model drives bottom-up adoption – engineers can freely trial and implement RudderStack in their own stack, which helps the product spread within organizations organically.
On top of the open-source foundation, RudderStack offers managed cloud services and enterprise features as the commercial offering. In other words, “anyone can use the open source version; the paid version includes premium enterprise features (e.g. advanced transformations, governance tools, single sign-on) and official support”. This model mirrors other successful open-source companies and is designed to convert a fraction of free users into paying customers once they require scale or enterprise capabilities.
RudderStack’s go-to-market strategy is therefore developer-centric: it targets data engineers with technical documentation and a community Slack, rather than traditional marketing to end-business users. This strategy contrasts with traditional CDPs that often sell top-down to marketing departments. Another key aspect of the business model is leveraging the “warehouse-first” architecture as a selling point.
Because RudderStack pipelines send data to the customer’s own databases (e.g. Snowflake, Redshift) and do not persist data on RudderStack’s servers, the solution appeals to companies with strict data privacy requirements and those aiming to reduce costs by using existing data infrastructure.
Cloud providers also have an incentive to recommend RudderStack, since its usage increases consumption of cloud data warehousing and storage resources. This has led to strategic partnerships (for example, with Snowflake and AWS) to co-market solutions.
Overall, RudderStack’s business model is a product-led growth approach: offer a powerful free tool to gain adoption, then monetize through a scalable cloud service and enterprise-grade add-ons.
Revenue Streams of RudderStack
RudderStack generates revenue primarily through subscription fees for its cloud and enterprise products, built on a usage-based pricing framework. The company’s Cloud SaaS offering has tiered plans that charge based on the volume of data events processed. Unlike many older CDPs that charged per monthly active user or device, RudderStack employs a transparent event-based pricing model, meaning customers pay according to the number of events (data points) they send through the platform.
For example, organizations can start on a free tier (up to a certain event quota per month) and then upgrade to paid plans as their data volume grows. This usage-aligned model ensures that costs scale predictably with the value derived, a response to customer concerns about unpredictable bills from other vendors.
In practical terms, RudderStack’s published pricing offers a free tier (e.g. up to hundreds of thousands of events per month) and a Starter tier at a flat rate for a higher event quota, then Growth and Enterprise tiers for custom volumes and advanced needs. The Enterprise offering can be deployed in the customer’s private cloud and includes additional features like identity resolution (RudderStack Profiles), advanced transformation functions, single sign-on (SSO), HIPAA compliance, and dedicated support.
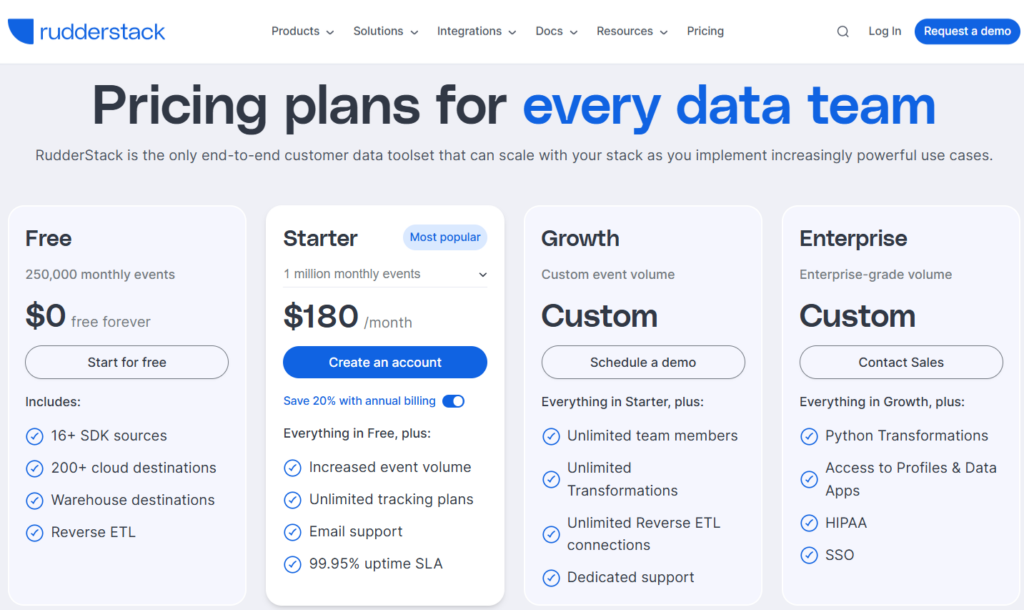
These features address complex requirements of larger organizations and are priced via annual contracts. Aside from subscription licenses, RudderStack may derive a smaller portion of revenue from professional services (such as implementation support or custom integrations), although this is not a core focus of the model.
The open-source community version itself does not generate revenue directly, but it significantly lowers customer acquisition costs by serving as a funnel for paid conversions.
In summary, RudderStack’s revenue streams are straightforward: recurring subscriptions tied to data volume and feature tiers, with an emphasis on transparency and alignment to customer usage.
(Table 1 illustrates RudderStack’s core revenue model.)
| Revenue Stream | Description | Pricing Approach |
|---|---|---|
| Open-Source Software (Community Edition) | Free-to-use core RudderStack server that companies can self-host. It seeds adoption and allows evaluation in production environments. | No license cost (open-source); no revenue directly. |
| Managed Cloud Service (SaaS) | Fully managed RudderStack Cloud with hosting, automatic scaling, and updates. Includes base features for event collection and routing. | Tiered subscription based on monthly event volume (e.g. Starter tier for ~1 million events/month). Predictable flat fee up to plan limits, upgrading as volume grows. |
| Enterprise & Advanced Features | Premium capabilities such as enriched Profiles (360° customer views), advanced transformations (e.g. Python code in pipeline), enterprise security (SSO, compliance), and priority support. Typically deployed in customer’s VPC or special cloud regions. | Custom-priced contracts (annual SaaS or license) tailored to the client’s event volume and requirements. Often involves a higher base fee plus support SLAs. |
Funding of RudderStack
Since its founding, RudderStack has attracted significant venture capital investment, reflecting confidence in the company’s approach to customer data management. As of 2025, the startup has raised a total of approximately $82 million over several rounds of financing.
RudderStack’s funding journey began with seed funding through its incubator: S28 Capital provided pre-seed capital in 2019 and went on to lead the official Seed round.
Subsequent rounds saw participation by top-tier investors.
The Series A in 2021 was led by Kleiner Perkins, a renowned Silicon Valley venture firm, bringing both capital and credibility to the young company. By early 2022, RudderStack secured a Series B of $56 million, led by Insight Partners (a global growth equity investor), with continued support from prior backers S28 Capital and Kleiner Perkins. This Series B brought RudderStack’s disclosed funding to $82 million. The infusion was earmarked for accelerating product development and go-to-market expansion, enabling RudderStack to scale its engineering and sales teams to meet demand.
Notably, RudderStack has not announced any Series C as of mid-2025 – a somewhat cautious approach in contrast to some competitors that raised larger later-stage rounds or exited via acquisition. The absence of a new round since 2022 suggests that RudderStack may be focusing on achieving sustainable growth (possibly approaching or exceeding the $10M–$20M annual revenue range) before seeking additional financing.
Major investors in RudderStack include S28 Capital (which incubated the company and whose partner Shvet Jain serves as executive chairman), Kleiner Perkins (lead of Series A), and Insight Partners (lead of Series B). These investors are known for backing successful infrastructure and software companies, and their involvement has provided RudderStack with not just capital but also strategic guidance.
(Table 2 provides an overview of RudderStack’s funding rounds.)
| Date | Round | Amount Raised | Lead Investor(s) | Notable Details |
|---|---|---|---|---|
| Jul 2019 | Pre-Seed | $1.5 million | S28 Capital | Initial incubation funding (convertible), used to build the first open-source prototype. S28’s Shvet Jain takes role as Executive Chairman. |
| May 2020 | Seed | $5 million | S28 Capital | Seed round to accelerate product development. Focused on open-source project growth and initial go-to-market efforts. |
| Jun 2021 | Series A | $21 million | Kleiner Perkins | Brought on Kleiner Perkins as lead VC (with S28 and Uncorrelated Ventures participating). Aimed at scaling the team and launching the “warehouse-first CDP for developers” to market. |
| Feb 2022 | Series B | $56 million | Insight Partners | Insight Partners led this round, with prior investors (Kleiner, S28) joining. Proceeds dedicated to growth and product expansion (e.g., introducing Profiles and advanced integrations). Total funding reached ~$82 million |
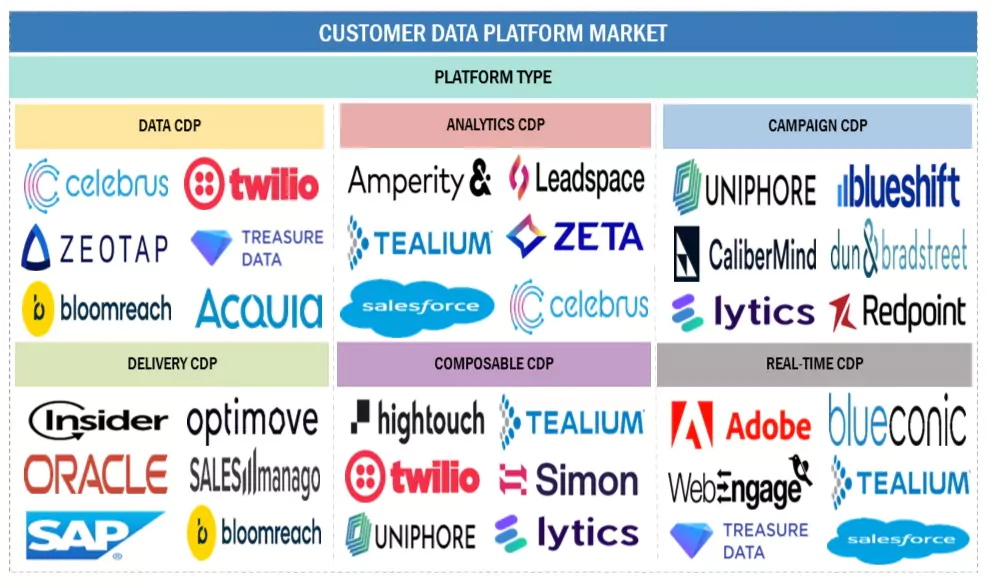
Competitors of RudderStack
RudderStack operates in a competitive landscape that spans both traditional Customer Data Platforms and modern data pipeline tools. Its primary competitors can be grouped into a few categories:
Traditional CDPs (Marketing-Focused):
The most prominent is Segment, founded in 2011 and considered a pioneer in the CDP space. Segment’s platform also collects and distributes customer events, though it operates as a closed SaaS service. Segment was acquired by Twilio for $3.2 billion in 2020, indicating the market value of customer data infrastructure.
Another established competitor is mParticle (founded 2013), which specializes in mobile and multi-channel customer data integration for enterprise brands. mParticle raised over $270 million in funding as an independent company, and was recently acquired by the e-commerce firm Rokt for $300 million (announced in early 2025).
The consolidation of Segment and mParticle into larger entities underscores the intense competition and strategic interest in this sector.
Other marketing-centric CDPs include Tealium, Adobe Experience Platform, Treasure Data, and Oracle CX Unity, which primarily target marketing users with turnkey customer 360 solutions. These incumbents generally provide broad suites but can be costly and less flexible in how data is stored or processed.
Data Pipeline and Integration Tools:
On another front, RudderStack faces competition from tools that handle parts of the data pipeline.
Fivetran and Airbyte, for example, focus on extract-transform-load (ETL/ELT) data integration, pulling data from cloud applications into warehouses.
While not CDPs per se, these tools overlap with RudderStack’s Cloud Extract feature (which ingests non-event data like CRM or support tickets into warehouses).
Apache Kafka and custom pipelines built on Kafka or cloud streaming services (like AWS Kinesis) are also alternatives for companies that prefer to build their own data routing infrastructure for event data.
Similarly, Snowplow Analytics is an open-source event tracking framework that appeals to data engineers; Snowplow enables collection of behavioral event data and storage in the customer’s warehouse, much like RudderStack’s event stream, though Snowplow users often need to assemble more components themselves.
Snowplow has raised about $55–60 million to date, highlighting a growing interest in open-source data tracking solutions.
Reverse ETL and Activation Platforms:
A newer category of competitors has emerged focusing on data activation, taking data out of data warehouses and pushing it into SaaS tools for marketing or sales use cases.
Companies like Hightouch and Census fall in this category. Both were founded around 2020 and have since grown rapidly by enabling warehouse data to be synced to tools like Salesforce, marketing automation platforms, or ad networks.
RudderStack competes with these by offering built-in “Warehouse Actions” (its term for reverse ETL) to send enriched data from the warehouse to downstream applications.
While Hightouch and Census are pure-play solutions with possibly deeper features in that niche, RudderStack’s strategy is to provide an integrated experience (collection and activation in one platform).
In summary, RudderStack’s competitors range from large integrated CDP suites to point solutions for data movement. The competitive dynamics are intense: big cloud vendors (Google, Amazon) also offer data pipeline components, and several startups vie for slices of the data stack.
However, RudderStack has carved a niche by combining elements of these capabilities under an open-source, warehouse-centric umbrella. Its closest direct competitor in spirit is arguably Segment (due to similar functionality), but RudderStack differentiates itself by targeting engineers and offering self-hosting.
The wave of acquisitions in the CDP space (e.g., Twilio/Segment, Rokt/mParticle, and even ActionIQ and Lytics being acquired in 2023–2024) may leave RudderStack as one of the few independent, pure-play customer data infrastructure providers. This could present opportunities to capture customers who seek vendor-neutral, flexible solutions in a post-consolidation market.
Competitive Advantage of RudderStack
1) Separation of Storage and Compute
RudderStack’s competitive advantage stems from both its technology architecture and its strategic positioning. One of the core technical differentiators is its separation of storage and compute for customer data. Unlike traditional CDPs that require you to send data into their proprietary storage, RudderStack processes events in real-time and then delivers them to the customer’s own database or warehouse, rather than storing it on RudderStack’s servers.
This design yields benefits in cost efficiency and scalability – companies aren’t paying RudderStack to warehouse their data and can leverage cheap, scalable cloud storage directly. An investor familiar with the space noted that RudderStack’s “end-to-end data pipelines optimized for data warehouses” provide a “best-in-class architecture [that] enables data engineers to eliminate data silos across teams” while accelerating advanced analytics use cases.
In practical terms, this means RudderStack can handle very large event volumes (billions of events per month) by riding on the scalability of platforms like Snowflake or Amazon S3, which is appealing for data-centric engineering teams.
2) Open-source and Developer-centric Approach
Another significant advantage is RudderStack’s open-source and developer-centric approach. Being open-source builds trust with engineers who can inspect the code and even run the platform on-premises for sensitive use cases. It also allows RudderStack to tap into community contributions and rapid feedback.
This is in stark contrast to competitors like Segment which are closed-source SaaS. Companies concerned with data privacy or vendor lock-in find RudderStack’s model attractive: the platform “is an open source alternative to traditional SaaS-based CDPs that store your data in their systems”, giving enterprises more control over their customer information.
Additionally, RudderStack caters to developers by supporting their workflows – for instance, it offers a CLI and supports version control and CI/CD for data pipelines (under its RSDX initiative). This developer-first design means integration and customization tend to be easier for engineering teams, turning what used to be a marketing tool into an engineering asset.
3) Cost transparency
RudderStack’s cost transparency and potentially lower total cost is another competitive edge. By charging based on events and allowing unlimited destinations (each event is billed once regardless of how many tools it’s sent to), RudderStack often comes out more economical for large volumes than competitors that charge per output or per user.
One early analysis suggested RudderStack could be up to 10× cheaper than hosted CDPs in high-volume scenarios, due to offloading storage costs. Whether this exact factor holds in all cases, RudderStack’s focus on efficiency resonates with companies facing ballooning data volumes.
Furthermore, RudderStack benefits from alignment with modern data stack trends. Its warehouse-centric philosophy has meshed well with the rise of cloud data warehouses and the “analytics engineering” movement. The company has secured partnerships and recognition in that ecosystem – for example, Snowflake (a leading data warehouse provider) identified RudderStack as a leading solution for data integration and activation in its 2023 Modern Marketing Data Stack report. This endorsement signals that RudderStack is viewed as a best-of-breed tool in enabling Customer 360 analytics on Snowflake’s platform. Such ecosystem validation amplifies RudderStack’s credibility against competitors.
In summary, RudderStack’s competitive advantages can be encapsulated in three points: (1) a flexible, warehouse-first architecture that scales and avoids lock-in, (2) an open-source, developer-friendly product that aligns with how modern data teams work, and (3) a cost-effective, transparent pricing model. Combined, these differentiators give RudderStack a strong value proposition for organizations (especially engineering-led ones) looking to build a customer data platform with more control and lower long-term costs than the incumbent solutions.
Products and Services of RudderStack
RudderStack offers a suite of products and features that together form a complete customer data pipeline – from data collection to activation – while maintaining a focus on integration with the customer’s data warehouse. The platform’s capabilities can be broken into several key components:
-
Event Stream Collection: This is RudderStack’s foundational service, equivalent to what Segment provides. Developers use RudderStack’s SDKs (16+ language and platform SDKs are available) to capture event data from websites, mobile apps, and backend servers in real time. RudderStack can also ingest events from third-party cloud services through webhook sources or integrations. Once captured, events are processed and routed through a streaming pipeline. RudderStack supports transformations on the fly – for example, engineers can write JavaScript or Python functions to mask or modify data in transit (a feature called RudderStack Transformations). This allows customization and enforcement of data policies (like scrubbing PII) before data lands in its destination. The event stream is the core around which other features are built, and it emphasizes reliability and low latency.
-
Cloud Extract (ELT): Recognizing that not all customer data comes as real-time events, RudderStack provides Cloud Extract connectors to pull data from various SaaS applications (such as Salesforce, Zendesk, Stripe, etc.) into the customer’s warehouse. These connectors perform batch ELT, essentially replicating the non-event customer data (e.g. CRM contacts, support tickets, billing data) into a unified repository. This complements the event stream by aggregating a more complete view of the customer. RudderStack’s Cloud Extract automates what might otherwise require separate ETL tools or custom scripts. By centralizing this in RudderStack, data engineers have a single pipeline system for all customer data.
-
Warehouse Synchronization & Storage: True to its “warehouse-first” design, RudderStack treats warehouses (like Snowflake, Amazon Redshift, Google BigQuery, etc.) as primary destinations. The platform can stream events directly into warehouses in real time or on a scheduled batch basis, creating up-to-date tables of raw events. It supports schema evolution and can work with the data infrastructure (for example, using Amazon S3 and Amazon Redshift’s COPY for efficient loading). By having data in the warehouse, companies can then run SQL analytics or feed machine learning models easily. RudderStack’s value-add is that it does the heavy lifting of translating event streams into warehouse tables. The platform does not monetize storage – the data resides with the customer’s own cloud account – which is a differentiator from fully-hosted CDPs.
-
Profiles and Identity Resolution: In 2023, RudderStack launched RudderStack Profiles, which adds identity stitching and customer 360 view building on top of the raw data. Profiles allows data teams to merge events and records into unified customer profiles (resolving identities across devices and data sources) and to compute user attributes or features (e.g. total purchases, last login time) directly in the warehouse. Essentially, RudderStack provides a framework and SQL templates to create a customer 360 table in the warehouse without manual SQL engineering. This feature was built in partnership with cloud data providers (e.g., an AWS Redshift integration) to ensure it can scale. Profiles also includes an identity graph capability – linking multiple identifiers (emails, device IDs, etc.) belonging to the same user – and ensures that downstream tools get a consistent view of each customer. By delivering this within the customer’s database, RudderStack avoids the “black box” problem of some CDPs and allows full transparency into how the profile is built. This product elevates RudderStack from just pipelines to a more complete CDP, since identity resolution and unified profiles are central to customer data platforms.
-
Reverse ETL and Activation: Once data and profiles are in the warehouse, RudderStack enables activation, meaning pushing the enriched data out to business tools to drive action. The Warehouse Actions/Reverse ETL feature lets engineers define queries or models in the warehouse and then send the results (e.g., a list of high-value customers or predictive scores) to over 200 downstream applications like marketing automation platforms, ad networks, or customer support tools. This capability parallels dedicated reverse ETL products and ensures that the single customer view in the warehouse can be used to personalize marketing campaigns or sales outreach in near-real time. Additionally, RudderStack introduced a Real-Time API for activation (Profiles API) – essentially an endpoint to retrieve profile attributes on the fly for use in applications (for example, to personalize a web experience for a user as they log in). With over 200 pre-built integrations to SaaS destinations, RudderStack covers a wide range of tools where customer data needs to be sent – from analytics tools like Amplitude or Mixpanel to advertising platforms and customer success tools. The breadth of integrations is crucial, as it matches Segment’s competitive advantage of having a large connector ecosystem.
-
Data Governance and Quality: Alongside pure data movement, RudderStack offers features to govern the data. This includes Tracking Plans and schema enforcement – teams can define expected event structures and RudderStack will detect violations or unexpected events. The platform’s Data Catalog features allow tracking of metadata for events and properties, helping with documentation and ensuring consistency. There are also data quality monitoring dashboards and the ability to replay events if a destination was temporarily unavailable. These governance capabilities are important for large teams to trust the data. They differentiate RudderStack’s offering as not just a “pipeline pipe” but a managed solution that ensures reliability and compliance (for instance, dropping events that don’t match the tracking plan to avoid garbage data downstream).
Overall, RudderStack’s product suite is quite comprehensive for a company of its size. By 2025, it effectively delivers what can be called a “warehouse-native CDP”: it has the Collection layer (SDKs, event stream, ELT), Unification layer (identity resolution and profile building in warehouse), and Activation layer (reverse ETL, real-time APIs). Importantly, all of this is offered with a developer experience in mind – through APIs, SQL, and code – rather than only a point-and-click UI. This resonates with data teams who want flexibility. The company continually updates its integrations and launches features (for example, in late 2022 it added Python Transformations for more advanced real-time data manipulation). In partnership announcements, RudderStack has highlighted that customers can achieve outcomes like significantly improved marketing ROI by using its Profiles and activation features on top of their warehouse.
In summary, RudderStack’s products and services cover the full lifecycle of customer data: from ingestion of raw events, through processing/unification into meaningful profiles, to activation of insights in business tools. This end-to-end approach, delivered in a warehouse-centric manner, is what sets RudderStack’s service portfolio apart from many competitors who handle only fragments of that pipeline.
Conclusion
RudderStack’s brand story and strategic trajectory illustrate how a clear technical vision can create a strong competitive position in a dynamic market. In just a few years, the company has evolved from a niche open-source project into a recognized player in customer data infrastructure, backed by reputable investors and used by thousands of companies. Its founding ethos – empowering engineers to own and accelerate customer data management – remains evident in its open-core business model and product design.
Strategically, RudderStack has differentiated itself through its warehouse-native approach and commitment to not storing customer data, aligning perfectly with the modern data stack movement and privacy-conscious clients. This approach has yielded tangible success: RudderStack reported over 300% growth in revenue and customer count in 2021, and it counts high-profile brands like AllBirds and Crate & Barrel among its users.
Moving forward, RudderStack faces the dual challenge of scaling up in a competitive environment while maintaining the developer trust it has built. The market is not standing still – larger incumbents are integrating vertically, and recent acquisitions of CDP firms indicate potential consolidation pressures.
However, being one of the few independent and open solutions left also puts RudderStack in a favorable spot for organizations seeking an alternative to big-cloud or big-martech offerings. Its strong emphasis on engineering use cases and cost efficiency could continue to win over data teams that are dissatisfied with older CDPs. The company’s roadmap of deeper warehouse integration, more real-time features, and AI/ML capabilities (e.g. simplifying predictive modeling via warehouse data) suggests it is aware of the need to keep innovating.
In conclusion, RudderStack’s story is one of bridging the gap between raw data plumbing and business outcomes. It has crafted a brand around being the “CDP for developers” and a strategic position as the enabler of customer data stacks in the cloud era. The formal analysis of its founding, model, and strategy reveals a startup that is both pragmatic and ambitious: pragmatic in leveraging open-source and existing cloud infrastructure, yet ambitious in aiming to become the primary platform through which all customer data flows.
As of 2025, RudderStack stands as a testament to how focusing on the right user base (in this case, data engineers) and technology trend (warehouse-centric analytics) can build a robust business in a short time. The next chapters of its story – whether it continues as a high-growth independent company, reaches profitability, or becomes an attractive acquisition target – will depend on how well it capitalizes on its competitive advantages in the evolving landscape of customer data technology. The evidence so far suggests a strong foundation and a clear strategic path for RudderStack, making it a noteworthy company in the data infrastructure domain.
Also Read: Hightouch – Founders, Business Model, Funding & Competitors
To read more content like this, subscribe to our newsletter


